
The Synthetic Data Generation Market size is rapidly gaining traction as organizations seek innovative ways to overcome challenges related to data scarcity, privacy, and compliance. Synthetic data, created through algorithms and simulation techniques, mimics real-world datasets without exposing sensitive information. This technology is increasingly being adopted across industries such as healthcare, finance, retail, and autonomous systems, where data accuracy and security are critical. With growing reliance on artificial intelligence and machine learning, synthetic data generation is emerging as a reliable solution to fuel model training and testing at scale.
The market is being propelled by the increasing demand for data-driven decision-making and the rising regulatory emphasis on data privacy. Traditional data collection often faces limitations such as high costs, lengthy processes, and compliance risks, especially under regulations like GDPR and CCPA. Synthetic data helps bridge this gap by offering realistic datasets that protect sensitive information while still maintaining accuracy for predictive modeling and analytics. This shift is enabling companies to reduce dependency on large volumes of actual consumer or patient data, thereby lowering privacy risks and operational costs.
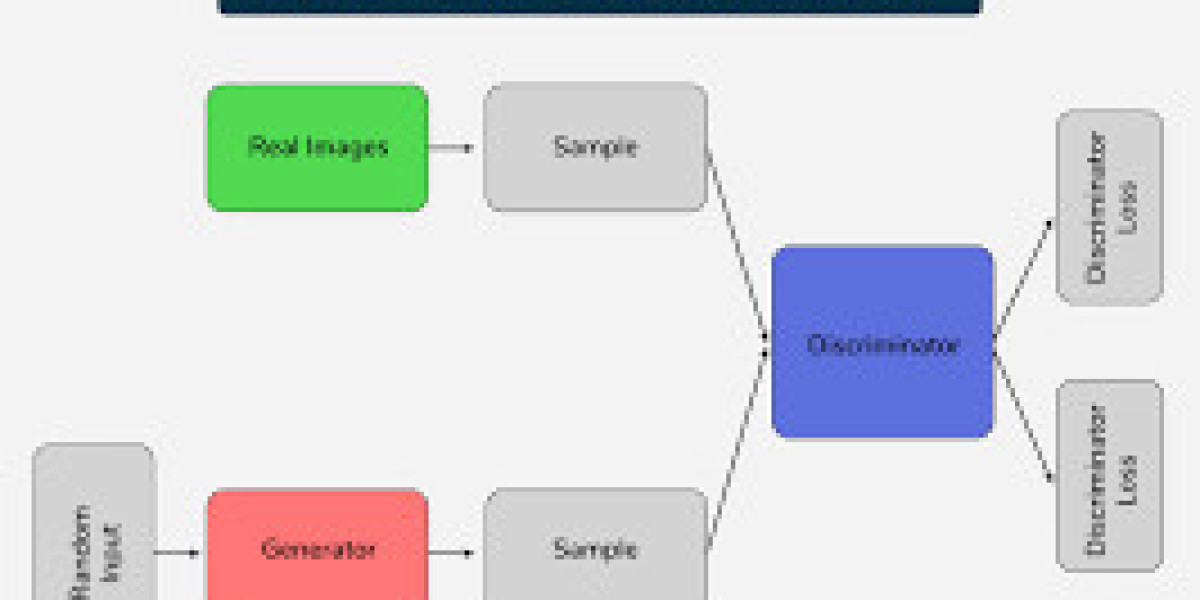
In addition to addressing privacy concerns, synthetic data generation is proving essential for innovation in machine learning. AI models often struggle with data imbalance, bias, or lack of diversity in training datasets. By leveraging synthetic data, businesses can create balanced, scalable, and varied datasets, enhancing the performance and fairness of AI systems. Industries like autonomous driving, robotics, and fraud detection are especially benefitting from this approach, as they require large, diverse datasets to simulate countless scenarios for effective training and deployment.
Technological advancements are also shaping the future of the synthetic data generation market. The use of generative adversarial networks (GANs), advanced simulations, and differential privacy techniques is making synthetic data more realistic and usable across complex applications. As cloud adoption grows, synthetic data generation tools are increasingly being integrated into enterprise data ecosystems, supporting large-scale analytics and innovation. Moreover, startups and established players alike are investing in AI-driven platforms to make synthetic data more accessible, customizable, and cost-efficient for organizations worldwide.
Regionally, North America is expected to dominate the synthetic data generation market due to the strong presence of AI research, technology providers, and stringent data privacy regulations. Europe follows closely with its proactive stance on data protection laws, while Asia-Pacific is witnessing rapid growth driven by digital transformation initiatives and expanding AI adoption in countries like China, Japan, and India. The global momentum indicates that synthetic data will play a pivotal role in shaping digital ecosystems and ensuring data security in the future.
Looking ahead, the Synthetic Data Generation Market is poised for significant growth as enterprises increasingly recognize its value in enabling innovation while safeguarding compliance. The convergence of AI, big data, and privacy-centric technologies will continue to fuel market expansion. With rising investments and adoption across diverse sectors, synthetic data is expected to become a cornerstone of digital transformation strategies, reshaping how organizations handle data, train AI systems, and accelerate time-to-market for intelligent solutions.













